Audiostream auslesen aus HTML
-
Re: Wo werden Temporary Files(Stream) gespeichert?
Hallo Lilo & ander Nutzer,
da ich als IT-Unkundiger nach nunmehr einer halben Stunde Suche leider keine Lösung gefunden habe, wollte ich Euch mal wieder um freundliche Hilfe bitten.
Ich habe hier einen Link:
Hier kann ich einen Podcast direkt auf der Seite abspielen - so weit so gut...
Wie kann ich denn einen Link finden, der diesen Audiostream auch bspw. auf VLC abspielt. Habe bereits vergeblich nach "mp3" oder "swf" gesucht.
Entschuldigt bitte meine Laienhafte und fehlerhafte Formulierung/Darstellung und vielen Dank für Eure Unterstützung!
Schönen Abend an alle!
Stefan
-
@StefanSeifried said in Audiostream auslesen aus HTML:
Re: Wo werden Temporary Files(Stream) gespeichert?
Hallo Lilo & ander Nutzer,
noch eine URL mit einer Audio-Datei...
vielleicht habt Ihr ja hier eine Möglichkeit den Audiostream zu ermitteln?
-
@Gwen-Dragon
Danke Lilo, das hat - so wie ich erwartet hatte - natürlich funktioniert. Aber wo und wie hast Du diesen mp3-Link ausgelesen?
-
@Gwen-Dragon said in Audiostream auslesen aus HTML:
@StefanSeifried Ich komm an den Podcast bei Handelsblatt nicht ran, Paywall
 .
.Ja verstehe...
Das ist ja auch der Grund warum ich anderen ohne Abo diese Möglichkeit, z. B. via Mediaplayer zur Verfügung stellen möchte!
-
@Gwen-Dragon said in Audiostream auslesen aus HTML:
https://speech.zeit.de/article-file?length=full&type=mp3&uuid=6944d6d4-f573-45c4-9088-e1b922f67186
Hast Du vielleicht diese Zeile genutzt...
<meta property="og:audio" content="https://speech.zeit.de/article-file?length=full&type=mp3&uuid=6944d6d4-f573-45c4-9088-e1b922f67186" />
und den Link etwas geändert?
-
@Gwen-Dragon said in Audiostream auslesen aus HTML:
@StefanSeifried Ja, den Teil des HTML nahm ich, mit Verlaub.
Gut. Nur wie kann ein Laie wie ich wissen wonach er suchen muss. Der Originallink heißt ja in Teilen immer "&" "https://speech.zeit.de/article-file?length=full&type=mp3&uuid=6944d6d4-f573-45c4-9088-e1b922f67186" und so funktioniert das Ganze nicht.
Weiterhin ist nicht in jedem Quelltext die "mp3" sichtbar.
Gibt es einen "Trick" in Vivaldi wie ich vorgehen muss. Ist der Aufruf mit Quelltext überhaupt der Richtige?
-
@StefanSeifried said in Audiostream auslesen aus HTML:
@Gwen-Dragon said in Audiostream auslesen aus HTML:
@StefanSeifried Ja, den Teil des HTML nahm ich, mit Verlaub.
Gut. Nur wie kann ein Laie wie ich wissen wonach er suchen muss. Der Originallink heißt ja in Teilen immer "&" "https://speech.zeit.de/article-file?length=full&type=mp3&uuid=6944d6d4-f573-45c4-9088-e1b922f67186" und so funktioniert das Ganze nicht.
Weiterhin ist nich in jedem Quelltext die "mp3" sichtbar.
Gibt es einen "Trick" in Vivaldi wie ich vorgehen muss. Ist der Aufruf mit Quelltext überhaupt der Richtige?
Interessant...
Wenn ich hier den Originallink mit "&" eingebe, wird dieser immer automatisch und richtig ohne "amp" korrigiert - allerdings nur hier und nicht im VLC!
-
@Gwen-Dragon said in Audiostream auslesen aus HTML:
@StefanSeifried Manche Zeichen in URLs sidn in HTML anders kodiert.
Für VLC muss du&zu&machen.Letzte Frage um Dich/Euch nicht weiter zu belästigen...
Gibt es auch eine andere Möglichkeit einen Audiostream/Link in einer HTML zu identifizieren wenn es explizit keinen Eintrag wie mp3 gibt?
Beispielsweise ist in dem Handelsblatt-Link - den Du nicht öffnen konntest - kein Eintrag zu "mp3" vorhanden und trotzdem muss ja irgendwo "Audio" enthalten sein!
-
@Gwen-Dragon
Fein...dann herzlichen Dank - wie immer - für die freundliche Unterstützung und Hilfe!
Schönen Abend an alle hier im Forum!
Stefan Seifried
-
Die Audiodatei ist bei mir eine .opus, der Link steht direkt im Quelltext (Rechtsklick auf den Player, Element untersuchen). Ansonsten nutze ich die Erweiterung "uBlock Origin", die auch einen Logger mitbringt, über den sich häufig, aber nicht immer, die Links zu den abgespielten Audio- und Videodateien finden lassen.
-
Vielen Dank für Deinen ergänzenden Hinweis!
Erfolgreiche Woche an alle!
Stefan
-
@tob1as said in Audiostream auslesen aus HTML:
Die Audiodatei ist bei mir eine .opus, der Link steht direkt im Quelltext (Rechtsklick auf den Player, Element untersuchen). Ansonsten nutze ich die Erweiterung "uBlock Origin", die auch einen Logger mitbringt, über den sich häufig, aber nicht immer, die Links zu den abgespielten Audio- und Videodateien finden lassen.
Wie muss ich denn vorgehen, um den "Logger" - wie Du schreibst - in der Erweiterung ""uBlock Origin" zu nutzen bzw. um auf einer Internetseite die Audiodatei zu finden?
Danke für Deine Antwort idealerweise in einzelnen Schritten!
-
Mit dieser Erweiterung gelang es mir den Podcast herunterzuladen
Musik-Downloader
https://chrome.google.com/webstore/detail/music-downloader/iempladfkphdpimdljfckjlmgklmdchc -
@PetroL said in Audiostream auslesen aus HTML:
Mit dieser Erweiterung gelang es mir den Podcast herunterzuladen
Musik-Downloader
https://chrome.google.com/webstore/detail/music-downloader/iempladfkphdpimdljfckjlmgklmdchcDanke für den Hinweis. Allerdings geht es mir grundsätzlich darum, "eingebundene" Audiodateien aus einer Webseite auszulesen.
Als Beispiel vom heutigen Tage würde mich interessieren, wo im "Quelltext" der entsprechende Link steht und mit welchen "Mitteln" man diesen bzw. auch auf anderen HTML-Seiten, findet.
https://www.n-tv.de/politik/Wirecard-fuehrte-auch-Politiker-in-die-Irre-article22178918.html
-
Bei Dingen von denen ich nicht so viel Ahnung habe, lasse ich mir gern von spezialisierten Tools helfen
Wo das im Quelltext steht und wie man es extrahieren kann, kann ich dir nicht beantworten
-
Danke für Deine Antwort. Das hat mir in diesem speziellen Fall geholfen. ".m3u8" ist ein Audiostream. Kannst Du mir bitte noch verraten woher diese Angabe stammt, sofern Du nicht den Quelltext aufgerufen hast. Wie ist Deine Erweiterung zu verwenden, um auf diesen "Link" zu kommen - danke!
Meine heutige Anmerkung: Nach Installation hat der "Prozessstart" nicht funktioniert - so hatten das andere Nutzer leider auch berichtet.
-
@StefanSeifried Die meisten Websites machen es einem mehr oder weniger schwer, die Mediendatei auszulesen, wie @Gwen-Dragon bereits erwähnte. Daher gibt es auch keinen allgemeingültigen Weg. Bei manchen öffentlich-rechtlichen Angeboten findet sich der Link zur Mediendatei direkt im Quelltext (suche z.B. nach mp3 oder mp4 für Video) oder direkt und bequem per MediathekView.
Um den Logger von ublock Origin zu öffnen, klickst du auf das Icon der Erweiterung in der Menüleiste und dann auf das Logger-Symbol (siehe Screenshot).
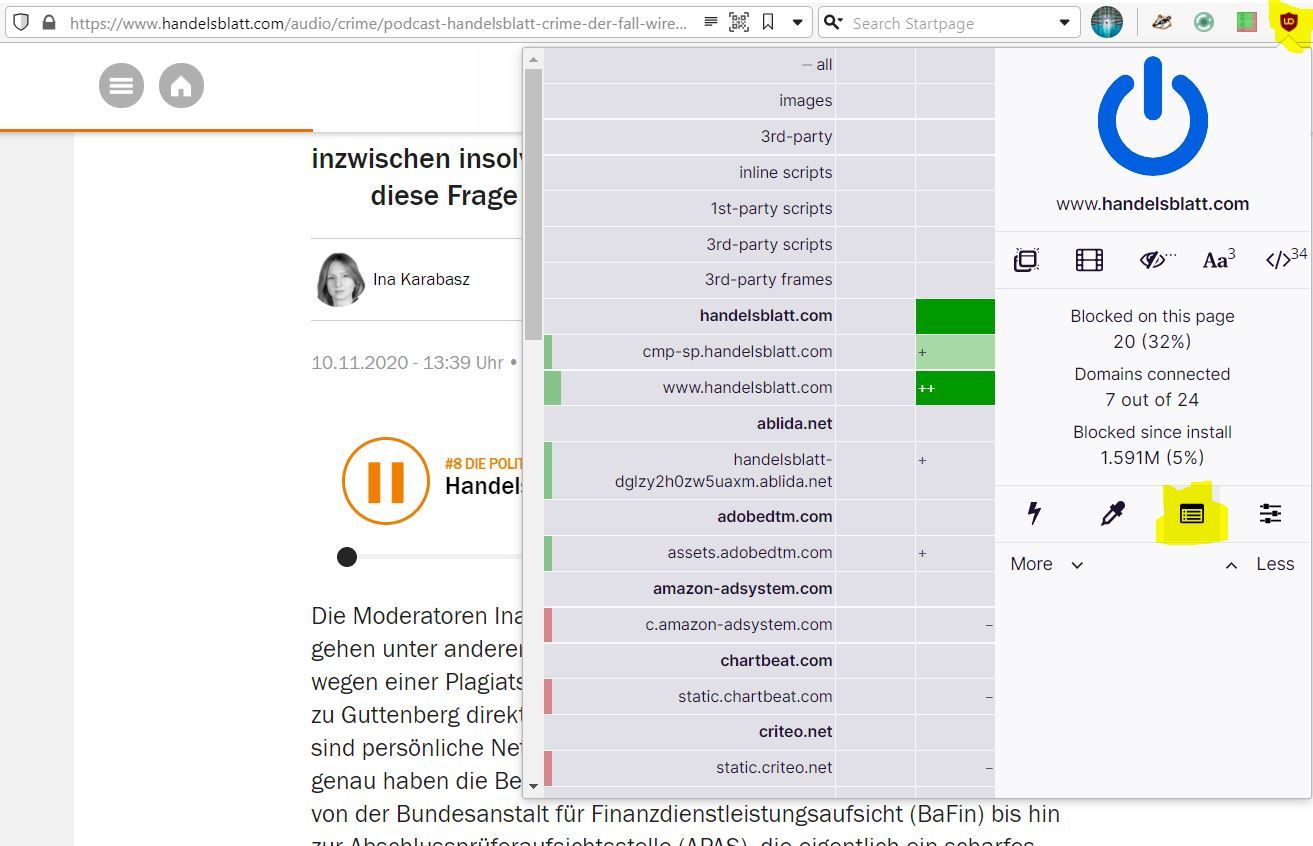
Dann lädst du die Website mit dem Medieninhalt ggf. nochmal neu und startest die Wiedergabe. Im Logger kannst du auch nach "media" filtern. Hier tauchen dann die entsprechenden Links auf.
In deinem ntv-Beispiel ist es nicht so einfach, da die Videodatei in einzelne .ts-Files aufgesplittet wird. Hier müssen andere Tools hinzugezogen werden.
-
Lieber Tobias,
vielen Dank für Deine umfangreiche Antwort. Jetzt bin ich als absoluter IT-Laie wenigstens ein bisschen schlauer! Werde bei Gelegenheit das Ganze nochmal probieren.
Schönen Tag und eine erfolgreichen Wochenverlauf!
Lieber Gruß aus Südhessen
Stefan Seifried
-
@StefanSeifried Gib einfach Bescheid, wenn du nochmal so einen Fall hast, dann schaue ich gerne, was sich machen lässt.
Für viele Websites kannst du auch youtube-dl nutzen, da gibt es für Windows eine graphische Oberfläche (GUI).
Hier findest du die Liste der unterstützten Seiten.
-
Ja prima Tobias,
sehr gerne werde ich bei Bedarf auf Dein freundliches Angebot zurückkommen!
Schönen Nachmittag/Abend noch,
Stefan